machine learning pipeline batch prediction designs
Introduction
In the machine learning pipeline, we may face the following scenario where we apply machine learning (ML) prediction to $customer * item$ combinations in an attempt to select the best item for each customer according to some criteria.
Flow 1
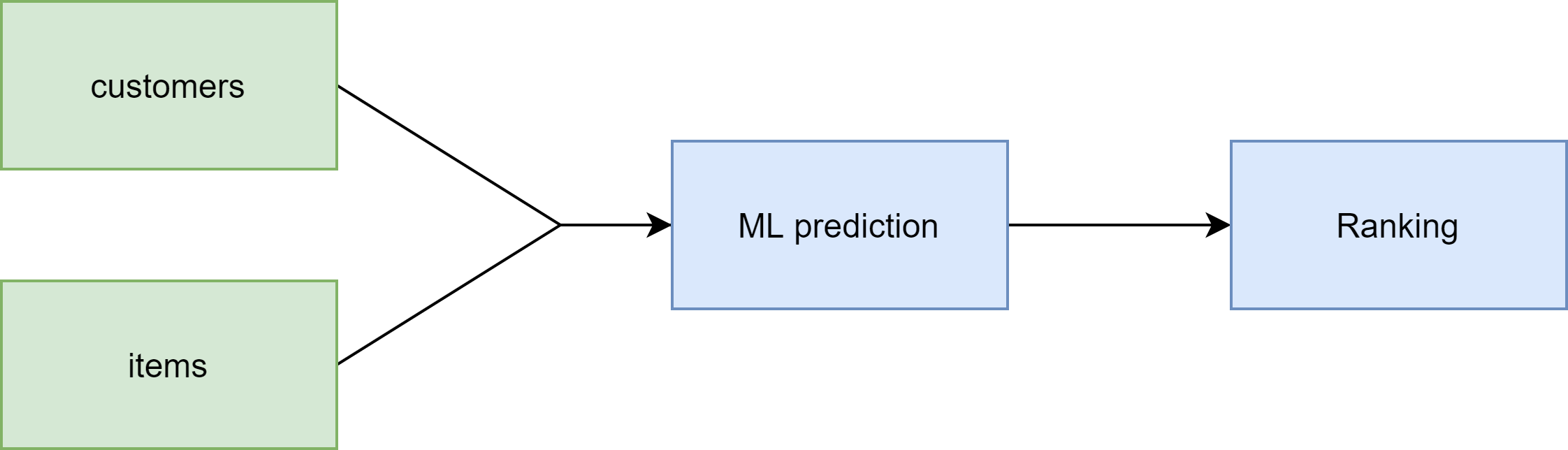
Given this scenario, we normally the following flow
- obtain customers data
- obtain items data
- run ML prediction on each customer-item combination
- rank the prediction per customer
This flow makes both the logical sense (business sense) also the physical sense in terms of how the code is implemented.
Flow 2

However, this is overly simplified in the real world. We often have constraints in the item or customer selection that limits which customer-item pair we can use in prediction. This constraint can be law, business contract, or downstream construct of how the selected customer-user combination should be used.
This means that we have to apply selection criteria on customers and items such that the ML prediction only runs on the eligible pairs
- obtain customers data
- filter eligible customers data
- obtain items data
- filter eligible items data
- run ML prediction on each eligible customer-item combination
- rank the prediction per eligible customer
This flow makes both the logical sense (business sense) also the physical sense in terms of how the code is implemented. The waterfall flow limits how many data points the ML prediction process should consume and in this way, optimize the computing resource needed to run the pipeline.
Flow 3

However, this kind of physical implementation may not work well in a rapidly changing consumer environment. We can have events happen spontaneously which affects the selection criteria. Any change in the customer or item selection criteria may require the pipeline to run from the beginning. This introduces a lot of additional computing time and limits how quickly we can react to change.
Thus, we have an alternate approach in the physical implementation
- obtain all customers data
- obtain all items data
- run ML prediction on each customer-item combination
- filter eligible customer-item combination
- rank the prediction per eligible customer
This allows the majority of the heavy lifting happened upfront. Since the ML prediction covers all customer-item combination, we don't need to rerun this process upon any change in the selection criteria. This allows us to quickly react to changes.
Flow 4

The aforementioned flow can be further optimized. Since the ML prediction and the criteria selection process are independent, we can run them in parallel to further shorten the time in the overall pipeline run time.
Conclusion
We've explored Flow 2 and Flow 4. Flow 2 fully optimized what's required by the logical flow by implementing the pipeline in the exact way that is described in the logical sense. Flow 4 uses an alternate flow where it allows the quick reaction to change but at the expense of spending extra computing resources and maybe a longer runtime. We can never have a perfect pipeline but given what is required, we can keep evolving the pipeline to make it more suitable.
Comments
Post a Comment